
From Generation to Execution: 4 Metrics, 3 Foundations of Agentic AI for CXOs
Why most agentic AI fails in production—and the 4 metrics plus 3 foundations CXOs must use to make execution real.

Most AI demos look incredible.
Most AI agents will quietly fail in production.
Not because the models aren't smart enough. Because companies are measuring the wrong things — and skipping the infrastructure underneath.
Here's the shift no one is preparing for:
A chatbot answers a question. An agent runs a process.
That means
- understanding context.
- Holding memory.
- Using tools.
- Making decisions.
- Escalating wisely.
- Producing outcomes.
The leadership question is changing from:
"Can we use AI in this workflow?"
To:
"Can this AI run this workflow better than we currently do?"
That is a completely different bar.
And if you're a CXO, your scorecard needs to change with it.
Four metrics will decide whether your agentic AI becomes a real asset, or an expensive experiment.
Three pieces of infrastructure will decide whether you can hit those metrics at all.
THE FOUR METRICS

1. SOLUTION ACCURACY
Not generic accuracy. Organizational accuracy.
A grammatically perfect answer that ignores your refund policy is wrong. An invoice extraction that misses your approval hierarchy is wrong. A customer reply that forgets the customer's history is wrong.
The real question isn't "Did the agent answer?"
It's: "Did the agent answer correctly for OUR business, OUR data, OUR exceptions, OUR rules?"
Speed without accuracy just makes mistakes faster.
2. TOKEN EFFICIENCY (cost per outcome)
Today: "Wow, the agent solved it." Tomorrow: "What did that solution cost?"
Agents call models. Retrieve context. Loop through reasoning. Trigger tools. Generate long outputs.
At one task, that's fine. At enterprise scale, it's unit economics.
The winners won't be the ones using the smartest model. They'll be the ones designing the smartest AI economics.
When to use a big model. When to use a small one. When to retrieve. When to summarize. When to stop.
That is the real engineering work no one is talking about yet.
3. HUMAN DEPENDENCE
Most "AI productivity" today is a quiet illusion.
Humans prepare the context. Humans correct the output. Humans re-enter the data. Humans approve the obvious. Humans handle every exception.
That isn't automation. That's AI-assisted manual work.
Real agentic AI knows:
- what it already knows
- what it should retrieve
- what it has learned before
- when human judgment is genuinely needed
If your agent keeps asking for information that already lives in your CRM, your tickets, your documents, or your past decisions — the system isn't intelligent. It's incomplete.
Humans should be used for judgment. Not as missing infrastructure.
4. TIME EFFICIENCY
Business runs on clocks.
Customers wait. Sales waits. Finance waits. Compliance waits.
An agent that is accurate but slow can still fail the business.
But here's the trap most leaders fall into:
"Tokens per second" is not the metric. "Time to a correct, usable outcome" is the metric.
A model that streams fast but triggers 12 tool calls is slow. A model that responds slowly but solves it in one pass is fast.
Measure the workflow. Not the model.

These four metrics fight each other.
Higher accuracy often increases cost. Lower human dependence requires deeper orchestration. Higher speed can compromise quality. Lower cost can compromise accuracy.
So stop asking "Is this agent good?"
Start asking:
Good for which workflow? At what cost? With what risk? With how much human involvement?
Customer support optimizes for speed and scale. Finance optimizes for accuracy and control. Compliance optimizes for trust and auditability. Sales ops optimizes for personalization and autonomy.
There is no universal best agent. Only the best-designed agent for a specific job.
THE INFRASTRUCTURE UNDERNEATH
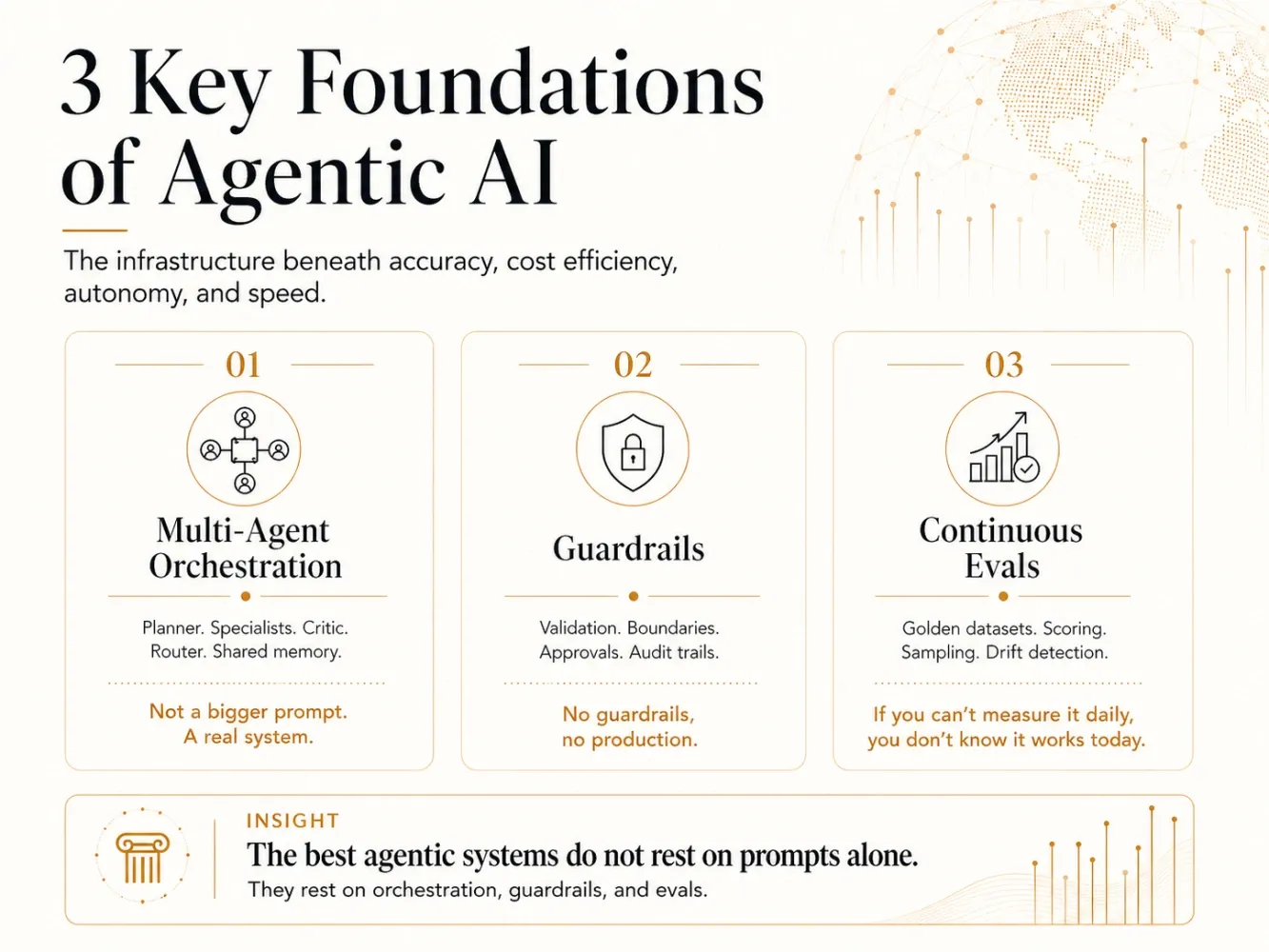
You can't hit those four metrics without three things most companies haven't built yet.
A. MULTI-AGENT ORCHESTRATION
A single agent cannot run a real business workflow.
Real workflows need a planner that decomposes the task. Specialists that execute parts. A critic that checks the work. A router that decides what goes where. A memory layer that connects them all.
That is multi-agent orchestration.
A monolithic prompt with ten tools attached is not an agent. It's a chatbot with extra steps.
The companies winning at agentic AI are not building bigger prompts. They are building systems of specialized agents that hand work to each other.
B. GUARDRAILS
If your agent can take action, it can take wrong action.
Send the wrong email. Approve the wrong invoice. Quote the wrong policy. Expose the wrong data. Trigger the wrong API.
Guardrails are not a compliance afterthought. They are the reason your agent stays trusted long enough to be used.
Input validation. Output validation. PII handling. Tool-use boundaries. Prompt injection defense. Approval thresholds for high-risk actions. Audit trails for everything.
No guardrails, no production.
C. CONTINUOUS EVALS
Most companies test their agent once. Declare it works. Ship it.
Then the model updates. The prompts drift. The data shifts. The edge cases multiply. The customer complains before anyone notices.
A continuous evals framework is the regression-testing layer of agentic AI.
Golden datasets. Automated scoring. Production sampling. Drift detection. Failure-mode tracking. Human-in-the-loop review for ambiguous cases.
If you can't measure your agent every day, you don't actually know if it's working today.
You are just hoping.
The four metrics are your scorecard. Orchestration, guardrails, and evals are your operating system.
You can't run the scorecard without the operating system.
THE NEW CXO SCORECARD
For the next 12 months, executives need to ask:
Is it correct for our context? What does one successful task cost? How often does it actually need a human? How fast does it reach a real outcome? Is it orchestrated, or just prompted? Is it guarded, or just hopeful? Is it evaluated continuously, or just at launch?
Phase 1 of AI was about generation. Phase 2 will be about execution.
And in execution, it doesn't matter whether your AI can talk.
It matters whether it can run the process — safely, repeatedly, and at a cost that makes sense.
Which gap do you think will hurt companies first — the wrong metric, missing orchestration, absent guardrails, or no continuous evals?